Tutorial: Coding the Agent to Learn from Atari¶
In this notebook, we will code out the atari wrappers following this paper.
# You might need to install these if you haven;t already
'''
!pip install torch
!pip install torchvision
!pip install numpy
!pip install matplotlib
!pip install gym
!pip install box2d-py
!pip install atari-py
'''
Random Action Episodes¶
## Random Guessing (No Learning)
import gym
import numpy as np
import matplotlib.pyplot as plt
env = gym.make('FrozenLake-v0')
n_games = 1000
win_pct = []
scores = []
for i in range(n_games):
done = False
obs = env.reset()
score = 0
while not done:
action = env.action_space.sample()
obs, reward, done, info = env.step(action)
score += reward
scores.append(score)
if i % 10 == 0:
average = np.mean(scores[-10:])
win_pct.append(average)
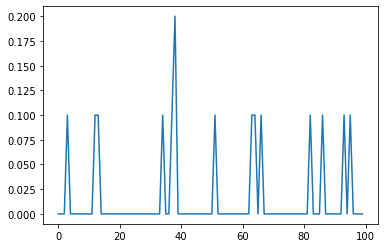
plt.plot(win_pct)
[<matplotlib.lines.Line2D at 0x1fe9caa69b0>]
Simple Q-Larning¶
## Q Learning
import numpy as np
class Agent():
def __init__ (self, lr, gamma, n_actions, n_states, eps_start, eps_end, eps_dec):
self.lr = lr
self.gamma = gamma
self.n_actions = n_actions
self.n_states = n_states
self.epsilon = eps_start
self.eps_min = eps_end
self.eps_dec = eps_dec
self.Q = {}
self.init_Q()
def init_Q(self):
for state in range(self.n_states):
for action in range(self.n_actions):
self.Q[(state, action)] = 0.0
def choose_action(self, state):
if np.random.random() < self.epsilon:
action = np.random.choice([i for i in range(self.n_actions)])
else:
actions = np.array([self.Q[(state, a)] for a in range(self.n_actions)])
action = np.argmax(actions)
return action
def decrement_epsilon(self):
self.epsilon = self.epsilon*self.eps_dec if self.epsilon > self.eps_min else self.eps_min
def learn(self, state, action, reward, state_):
actions = np.array([self.Q[(state_, a)] for a in range(self.n_actions)])
a_max = np.argmax(actions)
self.Q[(state, action)] += self.lr * (reward + self.gamma * self.Q[(state_, a_max)] - self.Q[(state, action)])
self.decrement_epsilon()
import gym
import matplotlib.pyplot as plt
import numpy as np
env = gym.make('FrozenLake-v0')
agent = Agent(lr = 0.001, gamma = 0.9, eps_start = 1.0, eps_end = 0.01, eps_dec = 0.9999995, n_actions = 4, n_states = 16)
scores = []
win_pct_lst = []
n_games = 500000
for i in range(n_games):
done = False
observation = env.reset()
score = 0
while not done:
action = agent.choose_action(observation)
observation_, reward, done, info = env.step(action)
agent.learn(observation, action, reward, observation_)
score += reward
observation = observation_
scores.append(score)
if i % 100 == 0:
win_pct = np.mean(scores[-100:])
win_pct_lst.append(win_pct)
if i % 1000 == 0:
print('episode', i, 'win_pct %.2f' % win_pct, 'epsilon %.2f' % agent.epsilon)
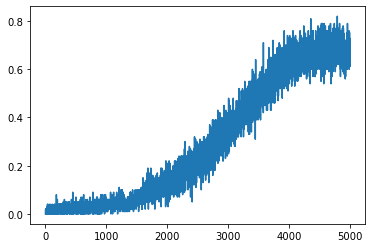
plt.plot(win_pct_lst)
episode 0 win_pct 0.00 epsilon 1.00
episode 1000 win_pct 0.02 epsilon 1.00
episode 2000 win_pct 0.02 epsilon 0.99
episode 3000 win_pct 0.02 epsilon 0.99
episode 4000 win_pct 0.00 epsilon 0.98
episode 5000 win_pct 0.01 epsilon 0.98
episode 6000 win_pct 0.00 epsilon 0.98
episode 7000 win_pct 0.04 epsilon 0.97
episode 8000 win_pct 0.00 epsilon 0.97
episode 9000 win_pct 0.00 epsilon 0.97
episode 10000 win_pct 0.03 epsilon 0.96
episode 11000 win_pct 0.00 epsilon 0.96
episode 12000 win_pct 0.00 epsilon 0.95
episode 13000 win_pct 0.02 epsilon 0.95
episode 14000 win_pct 0.02 epsilon 0.95
episode 15000 win_pct 0.01 epsilon 0.94
episode 16000 win_pct 0.01 epsilon 0.94
episode 17000 win_pct 0.02 epsilon 0.94
episode 18000 win_pct 0.08 epsilon 0.93
episode 19000 win_pct 0.02 epsilon 0.93
episode 20000 win_pct 0.00 epsilon 0.93
episode 21000 win_pct 0.01 epsilon 0.92
episode 22000 win_pct 0.02 epsilon 0.92
episode 23000 win_pct 0.04 epsilon 0.91
episode 24000 win_pct 0.04 epsilon 0.91
episode 25000 win_pct 0.00 epsilon 0.91
episode 26000 win_pct 0.02 epsilon 0.90
episode 27000 win_pct 0.01 epsilon 0.90
episode 28000 win_pct 0.00 epsilon 0.90
episode 29000 win_pct 0.03 epsilon 0.89
episode 30000 win_pct 0.04 epsilon 0.89
episode 31000 win_pct 0.01 epsilon 0.89
episode 32000 win_pct 0.00 epsilon 0.88
episode 33000 win_pct 0.01 epsilon 0.88
episode 34000 win_pct 0.00 epsilon 0.87
episode 35000 win_pct 0.04 epsilon 0.87
episode 36000 win_pct 0.03 epsilon 0.87
episode 37000 win_pct 0.01 epsilon 0.86
episode 38000 win_pct 0.04 epsilon 0.86
episode 39000 win_pct 0.05 epsilon 0.86
episode 40000 win_pct 0.00 epsilon 0.85
episode 41000 win_pct 0.01 epsilon 0.85
episode 42000 win_pct 0.01 epsilon 0.85
episode 43000 win_pct 0.02 epsilon 0.84
episode 44000 win_pct 0.03 epsilon 0.84
episode 45000 win_pct 0.02 epsilon 0.84
episode 46000 win_pct 0.03 epsilon 0.83
episode 47000 win_pct 0.05 epsilon 0.83
episode 48000 win_pct 0.03 epsilon 0.82
episode 49000 win_pct 0.02 epsilon 0.82
episode 50000 win_pct 0.00 epsilon 0.82
episode 51000 win_pct 0.01 epsilon 0.81
episode 52000 win_pct 0.03 epsilon 0.81
episode 53000 win_pct 0.01 epsilon 0.81
episode 54000 win_pct 0.04 epsilon 0.80
episode 55000 win_pct 0.02 epsilon 0.80
episode 56000 win_pct 0.02 epsilon 0.80
episode 57000 win_pct 0.01 epsilon 0.79
episode 58000 win_pct 0.00 epsilon 0.79
episode 59000 win_pct 0.02 epsilon 0.79
episode 60000 win_pct 0.01 epsilon 0.78
episode 61000 win_pct 0.02 epsilon 0.78
episode 62000 win_pct 0.01 epsilon 0.78
episode 63000 win_pct 0.03 epsilon 0.77
episode 64000 win_pct 0.02 epsilon 0.77
episode 65000 win_pct 0.03 epsilon 0.77
episode 66000 win_pct 0.01 epsilon 0.76
episode 67000 win_pct 0.02 epsilon 0.76
episode 68000 win_pct 0.03 epsilon 0.76
episode 69000 win_pct 0.02 epsilon 0.75
episode 70000 win_pct 0.05 epsilon 0.75
episode 71000 win_pct 0.02 epsilon 0.75
episode 72000 win_pct 0.04 epsilon 0.74
episode 73000 win_pct 0.04 epsilon 0.74
episode 74000 win_pct 0.04 epsilon 0.74
episode 75000 win_pct 0.02 epsilon 0.73
episode 76000 win_pct 0.05 epsilon 0.73
episode 77000 win_pct 0.02 epsilon 0.73
episode 78000 win_pct 0.04 epsilon 0.72
episode 79000 win_pct 0.02 epsilon 0.72
episode 80000 win_pct 0.03 epsilon 0.72
episode 81000 win_pct 0.02 epsilon 0.71
episode 82000 win_pct 0.01 epsilon 0.71
episode 83000 win_pct 0.04 epsilon 0.71
episode 84000 win_pct 0.03 epsilon 0.70
episode 85000 win_pct 0.00 epsilon 0.70
episode 86000 win_pct 0.02 epsilon 0.70
episode 87000 win_pct 0.06 epsilon 0.69
episode 88000 win_pct 0.06 epsilon 0.69
episode 89000 win_pct 0.01 epsilon 0.69
episode 90000 win_pct 0.02 epsilon 0.69
episode 91000 win_pct 0.03 epsilon 0.68
episode 92000 win_pct 0.07 epsilon 0.68
episode 93000 win_pct 0.02 epsilon 0.68
episode 94000 win_pct 0.03 epsilon 0.67
episode 95000 win_pct 0.04 epsilon 0.67
episode 96000 win_pct 0.01 epsilon 0.67
episode 97000 win_pct 0.02 epsilon 0.66
episode 98000 win_pct 0.08 epsilon 0.66
episode 99000 win_pct 0.02 epsilon 0.66
episode 100000 win_pct 0.05 epsilon 0.65
episode 101000 win_pct 0.01 epsilon 0.65
episode 102000 win_pct 0.03 epsilon 0.65
episode 103000 win_pct 0.04 epsilon 0.64
episode 104000 win_pct 0.02 epsilon 0.64
episode 105000 win_pct 0.04 epsilon 0.64
episode 106000 win_pct 0.05 epsilon 0.64
episode 107000 win_pct 0.09 epsilon 0.63
episode 108000 win_pct 0.07 epsilon 0.63
episode 109000 win_pct 0.02 epsilon 0.63
episode 110000 win_pct 0.02 epsilon 0.62
episode 111000 win_pct 0.04 epsilon 0.62
episode 112000 win_pct 0.09 epsilon 0.62
episode 113000 win_pct 0.04 epsilon 0.61
episode 114000 win_pct 0.01 epsilon 0.61
episode 115000 win_pct 0.04 epsilon 0.61
episode 116000 win_pct 0.04 epsilon 0.60
episode 117000 win_pct 0.09 epsilon 0.60
episode 118000 win_pct 0.02 epsilon 0.60
episode 119000 win_pct 0.06 epsilon 0.60
episode 120000 win_pct 0.04 epsilon 0.59
episode 121000 win_pct 0.02 epsilon 0.59
episode 122000 win_pct 0.01 epsilon 0.59
episode 123000 win_pct 0.05 epsilon 0.58
episode 124000 win_pct 0.06 epsilon 0.58
episode 125000 win_pct 0.06 epsilon 0.58
episode 126000 win_pct 0.03 epsilon 0.58
episode 127000 win_pct 0.04 epsilon 0.57
episode 128000 win_pct 0.04 epsilon 0.57
episode 129000 win_pct 0.08 epsilon 0.57
episode 130000 win_pct 0.05 epsilon 0.56
episode 131000 win_pct 0.03 epsilon 0.56
episode 132000 win_pct 0.06 epsilon 0.56
episode 133000 win_pct 0.03 epsilon 0.56
episode 134000 win_pct 0.05 epsilon 0.55
episode 135000 win_pct 0.01 epsilon 0.55
episode 136000 win_pct 0.05 epsilon 0.55
episode 137000 win_pct 0.04 epsilon 0.54
episode 138000 win_pct 0.01 epsilon 0.54
episode 139000 win_pct 0.02 epsilon 0.54
episode 140000 win_pct 0.04 epsilon 0.54
episode 141000 win_pct 0.05 epsilon 0.53
episode 142000 win_pct 0.05 epsilon 0.53
episode 143000 win_pct 0.07 epsilon 0.53
episode 144000 win_pct 0.04 epsilon 0.52
episode 145000 win_pct 0.08 epsilon 0.52
episode 146000 win_pct 0.04 epsilon 0.52
episode 147000 win_pct 0.07 epsilon 0.52
episode 148000 win_pct 0.06 epsilon 0.51
episode 149000 win_pct 0.05 epsilon 0.51
episode 150000 win_pct 0.05 epsilon 0.51
episode 151000 win_pct 0.07 epsilon 0.50
episode 152000 win_pct 0.09 epsilon 0.50
episode 153000 win_pct 0.06 epsilon 0.50
episode 154000 win_pct 0.03 epsilon 0.50
episode 155000 win_pct 0.07 epsilon 0.49
episode 156000 win_pct 0.10 epsilon 0.49
episode 157000 win_pct 0.09 epsilon 0.49
episode 158000 win_pct 0.04 epsilon 0.49
episode 159000 win_pct 0.11 epsilon 0.48
episode 160000 win_pct 0.07 epsilon 0.48
episode 161000 win_pct 0.04 epsilon 0.48
episode 162000 win_pct 0.07 epsilon 0.47
episode 163000 win_pct 0.07 epsilon 0.47
episode 164000 win_pct 0.02 epsilon 0.47
episode 165000 win_pct 0.07 epsilon 0.46
episode 166000 win_pct 0.11 epsilon 0.46
episode 167000 win_pct 0.07 epsilon 0.46
episode 168000 win_pct 0.13 epsilon 0.45
episode 169000 win_pct 0.07 epsilon 0.45
episode 170000 win_pct 0.05 epsilon 0.45
episode 171000 win_pct 0.10 epsilon 0.45
episode 172000 win_pct 0.09 epsilon 0.44
episode 173000 win_pct 0.09 epsilon 0.44
episode 174000 win_pct 0.06 epsilon 0.44
episode 175000 win_pct 0.10 epsilon 0.43
episode 176000 win_pct 0.15 epsilon 0.43
episode 177000 win_pct 0.07 epsilon 0.43
episode 178000 win_pct 0.15 epsilon 0.43
episode 179000 win_pct 0.09 epsilon 0.42
episode 180000 win_pct 0.12 epsilon 0.42
episode 181000 win_pct 0.08 epsilon 0.42
episode 182000 win_pct 0.16 epsilon 0.41
episode 183000 win_pct 0.10 epsilon 0.41
episode 184000 win_pct 0.12 epsilon 0.41
episode 185000 win_pct 0.07 epsilon 0.40
episode 186000 win_pct 0.13 epsilon 0.40
episode 187000 win_pct 0.07 epsilon 0.40
episode 188000 win_pct 0.10 epsilon 0.40
episode 189000 win_pct 0.12 epsilon 0.39
episode 190000 win_pct 0.03 epsilon 0.39
episode 191000 win_pct 0.14 epsilon 0.39
episode 192000 win_pct 0.08 epsilon 0.38
episode 193000 win_pct 0.17 epsilon 0.38
episode 194000 win_pct 0.14 epsilon 0.38
episode 195000 win_pct 0.13 epsilon 0.38
episode 196000 win_pct 0.12 epsilon 0.37
episode 197000 win_pct 0.14 epsilon 0.37
episode 198000 win_pct 0.07 epsilon 0.37
episode 199000 win_pct 0.12 epsilon 0.36
episode 200000 win_pct 0.13 epsilon 0.36
episode 201000 win_pct 0.16 epsilon 0.36
episode 202000 win_pct 0.08 epsilon 0.36
episode 203000 win_pct 0.06 epsilon 0.35
episode 204000 win_pct 0.12 epsilon 0.35
episode 205000 win_pct 0.18 epsilon 0.35
episode 206000 win_pct 0.13 epsilon 0.34
episode 207000 win_pct 0.17 epsilon 0.34
episode 208000 win_pct 0.09 epsilon 0.34
episode 209000 win_pct 0.13 epsilon 0.34
episode 210000 win_pct 0.11 epsilon 0.33
episode 211000 win_pct 0.10 epsilon 0.33
episode 212000 win_pct 0.16 epsilon 0.33
episode 213000 win_pct 0.08 epsilon 0.32
episode 214000 win_pct 0.16 epsilon 0.32
episode 215000 win_pct 0.19 epsilon 0.32
episode 216000 win_pct 0.18 epsilon 0.32
episode 217000 win_pct 0.16 epsilon 0.31
episode 218000 win_pct 0.12 epsilon 0.31
episode 219000 win_pct 0.11 epsilon 0.31
episode 220000 win_pct 0.07 epsilon 0.31
episode 221000 win_pct 0.14 epsilon 0.30
episode 222000 win_pct 0.17 epsilon 0.30
episode 223000 win_pct 0.22 epsilon 0.30
episode 224000 win_pct 0.24 epsilon 0.30
episode 225000 win_pct 0.17 epsilon 0.29
episode 226000 win_pct 0.12 epsilon 0.29
episode 227000 win_pct 0.14 epsilon 0.29
episode 228000 win_pct 0.14 epsilon 0.29
episode 229000 win_pct 0.12 epsilon 0.28
episode 230000 win_pct 0.10 epsilon 0.28
episode 231000 win_pct 0.20 epsilon 0.28
episode 232000 win_pct 0.18 epsilon 0.28
episode 233000 win_pct 0.16 epsilon 0.27
episode 234000 win_pct 0.26 epsilon 0.27
episode 235000 win_pct 0.20 epsilon 0.27
episode 236000 win_pct 0.18 epsilon 0.27
episode 237000 win_pct 0.12 epsilon 0.26
episode 238000 win_pct 0.18 epsilon 0.26
episode 239000 win_pct 0.13 epsilon 0.26
episode 240000 win_pct 0.13 epsilon 0.26
episode 241000 win_pct 0.05 epsilon 0.25
episode 242000 win_pct 0.22 epsilon 0.25
episode 243000 win_pct 0.17 epsilon 0.25
episode 244000 win_pct 0.15 epsilon 0.25
episode 245000 win_pct 0.18 epsilon 0.24
episode 246000 win_pct 0.25 epsilon 0.24
episode 247000 win_pct 0.18 epsilon 0.24
episode 248000 win_pct 0.24 epsilon 0.24
episode 249000 win_pct 0.20 epsilon 0.23
episode 250000 win_pct 0.22 epsilon 0.23
episode 251000 win_pct 0.27 epsilon 0.23
episode 252000 win_pct 0.20 epsilon 0.23
episode 253000 win_pct 0.24 epsilon 0.22
episode 254000 win_pct 0.23 epsilon 0.22
episode 255000 win_pct 0.27 epsilon 0.22
episode 256000 win_pct 0.10 epsilon 0.22
episode 257000 win_pct 0.22 epsilon 0.22
episode 258000 win_pct 0.25 epsilon 0.21
episode 259000 win_pct 0.22 epsilon 0.21
episode 260000 win_pct 0.22 epsilon 0.21
episode 261000 win_pct 0.25 epsilon 0.21
episode 262000 win_pct 0.31 epsilon 0.20
episode 263000 win_pct 0.28 epsilon 0.20
episode 264000 win_pct 0.26 epsilon 0.20
episode 265000 win_pct 0.19 epsilon 0.20
episode 266000 win_pct 0.22 epsilon 0.20
episode 267000 win_pct 0.28 epsilon 0.19
episode 268000 win_pct 0.27 epsilon 0.19
episode 269000 win_pct 0.23 epsilon 0.19
episode 270000 win_pct 0.28 epsilon 0.19
episode 271000 win_pct 0.25 epsilon 0.19
episode 272000 win_pct 0.21 epsilon 0.18
episode 273000 win_pct 0.29 epsilon 0.18
episode 274000 win_pct 0.32 epsilon 0.18
episode 275000 win_pct 0.16 epsilon 0.18
episode 276000 win_pct 0.33 epsilon 0.18
episode 277000 win_pct 0.26 epsilon 0.17
episode 278000 win_pct 0.30 epsilon 0.17
episode 279000 win_pct 0.35 epsilon 0.17
episode 280000 win_pct 0.22 epsilon 0.17
episode 281000 win_pct 0.36 epsilon 0.17
episode 282000 win_pct 0.26 epsilon 0.16
episode 283000 win_pct 0.29 epsilon 0.16
episode 284000 win_pct 0.24 epsilon 0.16
episode 285000 win_pct 0.30 epsilon 0.16
episode 286000 win_pct 0.28 epsilon 0.16
episode 287000 win_pct 0.29 epsilon 0.15
episode 288000 win_pct 0.35 epsilon 0.15
episode 289000 win_pct 0.32 epsilon 0.15
episode 290000 win_pct 0.31 epsilon 0.15
episode 291000 win_pct 0.27 epsilon 0.15
episode 292000 win_pct 0.22 epsilon 0.14
episode 293000 win_pct 0.37 epsilon 0.14
episode 294000 win_pct 0.34 epsilon 0.14
episode 295000 win_pct 0.30 epsilon 0.14
episode 296000 win_pct 0.35 epsilon 0.14
episode 297000 win_pct 0.28 epsilon 0.14
episode 298000 win_pct 0.41 epsilon 0.13
episode 299000 win_pct 0.29 epsilon 0.13
episode 300000 win_pct 0.37 epsilon 0.13
episode 301000 win_pct 0.37 epsilon 0.13
episode 302000 win_pct 0.26 epsilon 0.13
episode 303000 win_pct 0.45 epsilon 0.13
episode 304000 win_pct 0.35 epsilon 0.12
episode 305000 win_pct 0.33 epsilon 0.12
episode 306000 win_pct 0.32 epsilon 0.12
episode 307000 win_pct 0.35 epsilon 0.12
episode 308000 win_pct 0.34 epsilon 0.12
episode 309000 win_pct 0.40 epsilon 0.12
episode 310000 win_pct 0.37 epsilon 0.11
episode 311000 win_pct 0.42 epsilon 0.11
episode 312000 win_pct 0.43 epsilon 0.11
episode 313000 win_pct 0.43 epsilon 0.11
episode 314000 win_pct 0.44 epsilon 0.11
episode 315000 win_pct 0.32 epsilon 0.11
episode 316000 win_pct 0.46 epsilon 0.10
episode 317000 win_pct 0.37 epsilon 0.10
episode 318000 win_pct 0.52 epsilon 0.10
episode 319000 win_pct 0.36 epsilon 0.10
episode 320000 win_pct 0.36 epsilon 0.10
episode 321000 win_pct 0.35 epsilon 0.10
episode 322000 win_pct 0.39 epsilon 0.10
episode 323000 win_pct 0.39 epsilon 0.09
episode 324000 win_pct 0.40 epsilon 0.09
episode 325000 win_pct 0.49 epsilon 0.09
episode 326000 win_pct 0.39 epsilon 0.09
episode 327000 win_pct 0.43 epsilon 0.09
episode 328000 win_pct 0.45 epsilon 0.09
episode 329000 win_pct 0.43 epsilon 0.09
episode 330000 win_pct 0.48 epsilon 0.09
episode 331000 win_pct 0.43 epsilon 0.08
episode 332000 win_pct 0.42 epsilon 0.08
episode 333000 win_pct 0.43 epsilon 0.08
episode 334000 win_pct 0.48 epsilon 0.08
episode 335000 win_pct 0.49 epsilon 0.08
episode 336000 win_pct 0.49 epsilon 0.08
episode 337000 win_pct 0.49 epsilon 0.08
episode 338000 win_pct 0.40 epsilon 0.08
episode 339000 win_pct 0.47 epsilon 0.07
episode 340000 win_pct 0.60 epsilon 0.07
episode 341000 win_pct 0.45 epsilon 0.07
episode 342000 win_pct 0.49 epsilon 0.07
episode 343000 win_pct 0.56 epsilon 0.07
episode 344000 win_pct 0.58 epsilon 0.07
episode 345000 win_pct 0.50 epsilon 0.07
episode 346000 win_pct 0.51 epsilon 0.07
episode 347000 win_pct 0.50 epsilon 0.07
episode 348000 win_pct 0.47 epsilon 0.06
episode 349000 win_pct 0.49 epsilon 0.06
episode 350000 win_pct 0.55 epsilon 0.06
episode 351000 win_pct 0.49 epsilon 0.06
episode 352000 win_pct 0.49 epsilon 0.06
episode 353000 win_pct 0.46 epsilon 0.06
episode 354000 win_pct 0.48 epsilon 0.06
episode 355000 win_pct 0.56 epsilon 0.06
episode 356000 win_pct 0.49 epsilon 0.06
episode 357000 win_pct 0.52 epsilon 0.06
episode 358000 win_pct 0.71 epsilon 0.06
episode 359000 win_pct 0.57 epsilon 0.05
episode 360000 win_pct 0.48 epsilon 0.05
episode 361000 win_pct 0.55 epsilon 0.05
episode 362000 win_pct 0.45 epsilon 0.05
episode 363000 win_pct 0.49 epsilon 0.05
episode 364000 win_pct 0.49 epsilon 0.05
episode 365000 win_pct 0.57 epsilon 0.05
episode 366000 win_pct 0.61 epsilon 0.05
episode 367000 win_pct 0.69 epsilon 0.05
episode 368000 win_pct 0.61 epsilon 0.05
episode 369000 win_pct 0.58 epsilon 0.05
episode 370000 win_pct 0.54 epsilon 0.04
episode 371000 win_pct 0.47 epsilon 0.04
episode 372000 win_pct 0.61 epsilon 0.04
episode 373000 win_pct 0.62 epsilon 0.04
episode 374000 win_pct 0.60 epsilon 0.04
episode 375000 win_pct 0.58 epsilon 0.04
episode 376000 win_pct 0.60 epsilon 0.04
episode 377000 win_pct 0.61 epsilon 0.04
episode 378000 win_pct 0.51 epsilon 0.04
episode 379000 win_pct 0.59 epsilon 0.04
episode 380000 win_pct 0.55 epsilon 0.04
episode 381000 win_pct 0.63 epsilon 0.04
episode 382000 win_pct 0.54 epsilon 0.04
episode 383000 win_pct 0.57 epsilon 0.04
episode 384000 win_pct 0.61 epsilon 0.04
episode 385000 win_pct 0.58 epsilon 0.03
episode 386000 win_pct 0.52 epsilon 0.03
episode 387000 win_pct 0.58 epsilon 0.03
episode 388000 win_pct 0.60 epsilon 0.03
episode 389000 win_pct 0.48 epsilon 0.03
episode 390000 win_pct 0.67 epsilon 0.03
episode 391000 win_pct 0.67 epsilon 0.03
episode 392000 win_pct 0.55 epsilon 0.03
episode 393000 win_pct 0.62 epsilon 0.03
episode 394000 win_pct 0.61 epsilon 0.03
episode 395000 win_pct 0.61 epsilon 0.03
episode 396000 win_pct 0.58 epsilon 0.03
episode 397000 win_pct 0.59 epsilon 0.03
episode 398000 win_pct 0.55 epsilon 0.03
episode 399000 win_pct 0.68 epsilon 0.03
episode 400000 win_pct 0.67 epsilon 0.03
episode 401000 win_pct 0.64 epsilon 0.03
episode 402000 win_pct 0.64 epsilon 0.03
episode 403000 win_pct 0.63 epsilon 0.02
episode 404000 win_pct 0.64 epsilon 0.02
episode 405000 win_pct 0.60 epsilon 0.02
episode 406000 win_pct 0.62 epsilon 0.02
episode 407000 win_pct 0.71 epsilon 0.02
episode 408000 win_pct 0.60 epsilon 0.02
episode 409000 win_pct 0.65 epsilon 0.02
episode 410000 win_pct 0.66 epsilon 0.02
episode 411000 win_pct 0.61 epsilon 0.02
episode 412000 win_pct 0.59 epsilon 0.02
episode 413000 win_pct 0.61 epsilon 0.02
episode 414000 win_pct 0.59 epsilon 0.02
episode 415000 win_pct 0.57 epsilon 0.02
episode 416000 win_pct 0.61 epsilon 0.02
episode 417000 win_pct 0.64 epsilon 0.02
episode 418000 win_pct 0.64 epsilon 0.02
episode 419000 win_pct 0.68 epsilon 0.02
episode 420000 win_pct 0.60 epsilon 0.02
episode 421000 win_pct 0.70 epsilon 0.02
episode 422000 win_pct 0.68 epsilon 0.02
episode 423000 win_pct 0.66 epsilon 0.02
episode 424000 win_pct 0.58 epsilon 0.02
episode 425000 win_pct 0.61 epsilon 0.02
episode 426000 win_pct 0.66 epsilon 0.02
episode 427000 win_pct 0.63 epsilon 0.02
episode 428000 win_pct 0.68 epsilon 0.02
episode 429000 win_pct 0.68 epsilon 0.02
episode 430000 win_pct 0.69 epsilon 0.01
episode 431000 win_pct 0.66 epsilon 0.01
episode 432000 win_pct 0.69 epsilon 0.01
episode 433000 win_pct 0.65 epsilon 0.01
episode 434000 win_pct 0.62 epsilon 0.01
episode 435000 win_pct 0.63 epsilon 0.01
episode 436000 win_pct 0.74 epsilon 0.01
episode 437000 win_pct 0.72 epsilon 0.01
episode 438000 win_pct 0.62 epsilon 0.01
episode 439000 win_pct 0.67 epsilon 0.01
episode 440000 win_pct 0.67 epsilon 0.01
episode 441000 win_pct 0.72 epsilon 0.01
episode 442000 win_pct 0.61 epsilon 0.01
episode 443000 win_pct 0.70 epsilon 0.01
episode 444000 win_pct 0.72 epsilon 0.01
episode 445000 win_pct 0.60 epsilon 0.01
episode 446000 win_pct 0.73 epsilon 0.01
episode 447000 win_pct 0.64 epsilon 0.01
episode 448000 win_pct 0.65 epsilon 0.01
episode 449000 win_pct 0.70 epsilon 0.01
episode 450000 win_pct 0.70 epsilon 0.01
episode 451000 win_pct 0.69 epsilon 0.01
episode 452000 win_pct 0.64 epsilon 0.01
episode 453000 win_pct 0.63 epsilon 0.01
episode 454000 win_pct 0.70 epsilon 0.01
episode 455000 win_pct 0.66 epsilon 0.01
episode 456000 win_pct 0.63 epsilon 0.01
episode 457000 win_pct 0.63 epsilon 0.01
episode 458000 win_pct 0.77 epsilon 0.01
episode 459000 win_pct 0.68 epsilon 0.01
episode 460000 win_pct 0.63 epsilon 0.01
episode 461000 win_pct 0.76 epsilon 0.01
episode 462000 win_pct 0.69 epsilon 0.01
episode 463000 win_pct 0.60 epsilon 0.01
episode 464000 win_pct 0.63 epsilon 0.01
episode 465000 win_pct 0.69 epsilon 0.01
episode 466000 win_pct 0.67 epsilon 0.01
episode 467000 win_pct 0.63 epsilon 0.01
episode 468000 win_pct 0.64 epsilon 0.01
episode 469000 win_pct 0.72 epsilon 0.01
episode 470000 win_pct 0.58 epsilon 0.01
episode 471000 win_pct 0.74 epsilon 0.01
episode 472000 win_pct 0.69 epsilon 0.01
episode 473000 win_pct 0.73 epsilon 0.01
episode 474000 win_pct 0.62 epsilon 0.01
episode 475000 win_pct 0.75 epsilon 0.01
episode 476000 win_pct 0.66 epsilon 0.01
episode 477000 win_pct 0.77 epsilon 0.01
episode 478000 win_pct 0.67 epsilon 0.01
episode 479000 win_pct 0.74 epsilon 0.01
episode 480000 win_pct 0.73 epsilon 0.01
episode 481000 win_pct 0.65 epsilon 0.01
episode 482000 win_pct 0.72 epsilon 0.01
episode 483000 win_pct 0.62 epsilon 0.01
episode 484000 win_pct 0.68 epsilon 0.01
episode 485000 win_pct 0.68 epsilon 0.01
episode 486000 win_pct 0.74 epsilon 0.01
episode 487000 win_pct 0.63 epsilon 0.01
episode 488000 win_pct 0.65 epsilon 0.01
episode 489000 win_pct 0.78 epsilon 0.01
episode 490000 win_pct 0.67 epsilon 0.01
episode 491000 win_pct 0.64 epsilon 0.01
episode 492000 win_pct 0.70 epsilon 0.01
episode 493000 win_pct 0.57 epsilon 0.01
episode 494000 win_pct 0.64 epsilon 0.01
episode 495000 win_pct 0.71 epsilon 0.01
episode 496000 win_pct 0.64 epsilon 0.01
episode 497000 win_pct 0.67 epsilon 0.01
episode 498000 win_pct 0.72 epsilon 0.01
episode 499000 win_pct 0.71 epsilon 0.01
[<matplotlib.lines.Line2D at 0x1fe9ee65be0>]
Simple DQN¶
## DQN
import gym
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch as T
import matplotlib.pyplot as plt
class LinearDeepQNetwork(nn.Module):
def __init__ (self, lr, n_actions, input_dims):
super(LinearDeepQNetwork, self).__init__()
self.fc1 = nn.Linear(*input_dims, 128)
self.fc2 = nn.Linear(128, n_actions)
self.optimizer = optim.Adam(self.parameters(), lr = lr)
self.loss = nn.MSELoss()
self.device = T.device('cuda:0' if T.cuda.is_available() else 'cpu')
print("My Device: ", self.device)
self.to(self.device)
def forward(self, state):
layer1 = F.relu(self.fc1(state))
actions = self.fc2(layer1)
return actions
class Agent():
def __init__ (self, input_dims, n_actions, lr = 0.0001, gamma = 0.99, epsilon = 1.0, eps_dec = 1e-5, eps_min = 0.01):
self.lr = lr
self.input_dims = input_dims
self.n_actions = n_actions
self.gamma = gamma
self.epsilon = epsilon
self.eps_dec = eps_dec
self.eps_min = eps_min
self.action_space = [i for i in range(self.n_actions)]
self.Q = LinearDeepQNetwork(self.lr, self.n_actions, self.input_dims)
def choose_action(self, observation):
if np.random.random() > self.epsilon:
state = T.tensor(observation, dtype = T.float).to(self.Q.device)
actions = self.Q.forward(state)
action = T.argmax(actions).item()
else:
action = np.random.choice(self.action_space)
return action
def decrement_epsilon(self):
self.epsilon = self.epsilon - self.eps_dec if self.epsilon > self.eps_min else self.eps_min
def learn(self, state, action, reward, state_):
self.Q.optimizer.zero_grad()
states = T.tensor(state, dtype = T.float).to(self.Q.device)
actions = T.tensor(action).to(self.Q.device)
rewards = T.tensor(reward).to(self.Q.device)
states_ = T.tensor(state_, dtype = T.float).to(self.Q.device)
q_pred = self.Q.forward(states)[actions]
q_next = self.Q.forward(states_).max()
q_target = reward + self.gamma*q_next
loss = self.Q.loss(q_target, q_pred).to(self.Q.device)
loss.backward()
self.Q.optimizer.step()
self.decrement_epsilon()
env = gym.make('CartPole-v1')
n_games = 10000
scores = []
eps_history = []
agent = Agent(
input_dims = env.observation_space.shape,
n_actions = env.action_space.n
)
for i in range(n_games):
score = 0
done = False
obs = env.reset()
while not done:
action = agent.choose_action(obs)
obs_, reward, done, info = env.step(action)
score += reward
agent.learn(obs, action, reward, obs_)
obs = obs_
scores.append(score)
eps_history.append(agent.epsilon)
if i % 100 == 0:
avg_score = np.mean(scores[-100:])
print('episode', i, 'score %.1f Avg_score %.1f epsilon %.2f'%(score, avg_score, agent.epsilon))
def plot_learning_curve(x, scores, epsilons):
fig = plt.figure()
ax = fig.add_subplot(111, label = "1")
ax2 = fig.add_subplot(111, label = "2", frame_on = False)
ax.plot(x, epsilons, color = "C0")
ax.set_xlabel("Training Steps", color = "C0")
ax.set_ylabel("Epsilon", color = "C0")
ax.tick_params(axis = 'x', colors = "C0")
ax.tick_params(axis = 'y', colors = "C0")
N = len(scores)
running_avg = np.empty(N)
for t in range(N):
running_avg[t] = np.mean(scores[max(0, t-100):(t+1)])
ax2.scatter(x, running_avg, color = "C1")
ax2.axes.get_xaxis().set_visible(False)
ax2.yaxis.tick_right()
ax2.set_ylabel('Score', color = "C1")
ax2.yaxis.set_label_position('right')
ax2.tick_params(axis = 'y', colors = "C1")
x = [i+1 for i in range(n_games)]
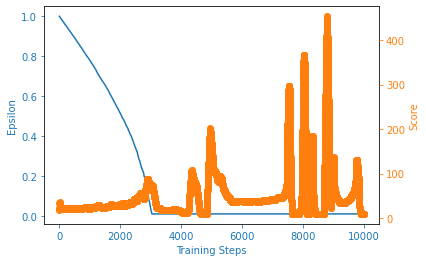
plot_learning_curve(x, scores, eps_history)
My Device: cuda:0
episode 0 score 18.0 Avg_score 18.0 epsilon 1.00
episode 100 score 14.0 Avg_score 22.2 epsilon 0.98
episode 200 score 38.0 Avg_score 22.2 epsilon 0.96
episode 300 score 12.0 Avg_score 20.8 epsilon 0.93
episode 400 score 24.0 Avg_score 21.8 epsilon 0.91
episode 500 score 27.0 Avg_score 22.1 epsilon 0.89
episode 600 score 9.0 Avg_score 21.7 epsilon 0.87
episode 700 score 12.0 Avg_score 22.6 epsilon 0.85
episode 800 score 17.0 Avg_score 22.9 epsilon 0.82
episode 900 score 25.0 Avg_score 22.3 epsilon 0.80
episode 1000 score 11.0 Avg_score 22.5 epsilon 0.78
episode 1100 score 24.0 Avg_score 23.8 epsilon 0.76
episode 1200 score 54.0 Avg_score 23.7 epsilon 0.73
episode 1300 score 41.0 Avg_score 28.9 epsilon 0.70
episode 1400 score 34.0 Avg_score 23.6 epsilon 0.68
episode 1500 score 10.0 Avg_score 22.7 epsilon 0.66
episode 1600 score 29.0 Avg_score 27.1 epsilon 0.63
episode 1700 score 24.0 Avg_score 30.6 epsilon 0.60
episode 1800 score 13.0 Avg_score 26.9 epsilon 0.57
episode 1900 score 14.0 Avg_score 29.3 epsilon 0.54
episode 2000 score 15.0 Avg_score 28.9 epsilon 0.51
episode 2100 score 22.0 Avg_score 28.6 epsilon 0.48
episode 2200 score 11.0 Avg_score 33.9 epsilon 0.45
episode 2300 score 25.0 Avg_score 33.1 epsilon 0.42
episode 2400 score 9.0 Avg_score 36.0 epsilon 0.38
episode 2500 score 13.0 Avg_score 40.0 epsilon 0.34
episode 2600 score 115.0 Avg_score 50.5 epsilon 0.29
episode 2700 score 10.0 Avg_score 50.3 epsilon 0.24
episode 2800 score 80.0 Avg_score 47.9 epsilon 0.19
episode 2900 score 92.0 Avg_score 87.6 epsilon 0.11
episode 3000 score 74.0 Avg_score 71.7 epsilon 0.03
episode 3100 score 88.0 Avg_score 54.2 epsilon 0.01
episode 3200 score 24.0 Avg_score 23.7 epsilon 0.01
episode 3300 score 19.0 Avg_score 21.4 epsilon 0.01
episode 3400 score 19.0 Avg_score 18.8 epsilon 0.01
episode 3500 score 21.0 Avg_score 18.8 epsilon 0.01
episode 3600 score 17.0 Avg_score 17.8 epsilon 0.01
episode 3700 score 19.0 Avg_score 18.6 epsilon 0.01
episode 3800 score 19.0 Avg_score 20.4 epsilon 0.01
episode 3900 score 19.0 Avg_score 17.3 epsilon 0.01
episode 4000 score 11.0 Avg_score 14.5 epsilon 0.01
episode 4100 score 10.0 Avg_score 11.4 epsilon 0.01
episode 4200 score 20.0 Avg_score 13.0 epsilon 0.01
episode 4300 score 102.0 Avg_score 76.8 epsilon 0.01
episode 4400 score 77.0 Avg_score 89.6 epsilon 0.01
episode 4500 score 70.0 Avg_score 71.4 epsilon 0.01
episode 4600 score 8.0 Avg_score 18.3 epsilon 0.01
episode 4700 score 8.0 Avg_score 9.4 epsilon 0.01
episode 4800 score 10.0 Avg_score 9.5 epsilon 0.01
episode 4900 score 104.0 Avg_score 128.1 epsilon 0.01
episode 5000 score 97.0 Avg_score 165.0 epsilon 0.01
episode 5100 score 105.0 Avg_score 103.6 epsilon 0.01
episode 5200 score 44.0 Avg_score 86.0 epsilon 0.01
episode 5300 score 130.0 Avg_score 87.8 epsilon 0.01
episode 5400 score 51.0 Avg_score 64.1 epsilon 0.01
episode 5500 score 24.0 Avg_score 51.7 epsilon 0.01
episode 5600 score 30.0 Avg_score 42.2 epsilon 0.01
episode 5700 score 33.0 Avg_score 36.1 epsilon 0.01
episode 5800 score 36.0 Avg_score 36.3 epsilon 0.01
episode 5900 score 37.0 Avg_score 38.3 epsilon 0.01
episode 6000 score 47.0 Avg_score 38.4 epsilon 0.01
episode 6100 score 46.0 Avg_score 36.8 epsilon 0.01
episode 6200 score 27.0 Avg_score 36.9 epsilon 0.01
episode 6300 score 42.0 Avg_score 37.4 epsilon 0.01
episode 6400 score 30.0 Avg_score 38.7 epsilon 0.01
episode 6500 score 35.0 Avg_score 36.0 epsilon 0.01
episode 6600 score 27.0 Avg_score 37.0 epsilon 0.01
episode 6700 score 38.0 Avg_score 39.6 epsilon 0.01
episode 6800 score 25.0 Avg_score 38.8 epsilon 0.01
episode 6900 score 39.0 Avg_score 40.6 epsilon 0.01
episode 7000 score 37.0 Avg_score 41.3 epsilon 0.01
episode 7100 score 41.0 Avg_score 42.9 epsilon 0.01
episode 7200 score 37.0 Avg_score 47.0 epsilon 0.01
episode 7300 score 42.0 Avg_score 45.8 epsilon 0.01
episode 7400 score 47.0 Avg_score 55.0 epsilon 0.01
episode 7500 score 500.0 Avg_score 247.9 epsilon 0.01
episode 7600 score 9.0 Avg_score 93.2 epsilon 0.01
episode 7700 score 10.0 Avg_score 9.3 epsilon 0.01
episode 7800 score 10.0 Avg_score 9.3 epsilon 0.01
episode 7900 score 11.0 Avg_score 14.9 epsilon 0.01
episode 8000 score 500.0 Avg_score 270.3 epsilon 0.01
episode 8100 score 10.0 Avg_score 119.9 epsilon 0.01
episode 8200 score 9.0 Avg_score 9.5 epsilon 0.01
episode 8300 score 47.0 Avg_score 183.0 epsilon 0.01
episode 8400 score 10.0 Avg_score 12.2 epsilon 0.01
episode 8500 score 8.0 Avg_score 9.3 epsilon 0.01
episode 8600 score 9.0 Avg_score 9.4 epsilon 0.01
episode 8700 score 500.0 Avg_score 79.4 epsilon 0.01
episode 8800 score 270.0 Avg_score 426.7 epsilon 0.01
episode 8900 score 11.0 Avg_score 41.3 epsilon 0.01
episode 9000 score 62.0 Avg_score 133.1 epsilon 0.01
episode 9100 score 46.0 Avg_score 48.2 epsilon 0.01
episode 9200 score 25.0 Avg_score 36.5 epsilon 0.01
episode 9300 score 30.0 Avg_score 33.3 epsilon 0.01
episode 9400 score 33.0 Avg_score 36.4 epsilon 0.01
episode 9500 score 51.0 Avg_score 40.9 epsilon 0.01
episode 9600 score 51.0 Avg_score 49.8 epsilon 0.01
episode 9700 score 96.0 Avg_score 68.5 epsilon 0.01
episode 9800 score 11.0 Avg_score 111.6 epsilon 0.01
episode 9900 score 10.0 Avg_score 12.7 epsilon 0.01
Import atari ROMs¶
%cd ..
d:\Github\Reinforcement_Learning
!python -m atari_py.import_roms ROMS/ROMS/
copying adventure.bin from ROMS/ROMS/ROMS\Adventure (1980) (Atari, Warren Robinett) (CX2613, CX2613P) (PAL).bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\adventure.bin
copying air_raid.bin from ROMS/ROMS/ROMS\Air Raid (Men-A-Vision) (PAL) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\air_raid.bin
copying alien.bin from ROMS/ROMS/ROMS\Alien (1982) (20th Century Fox Video Games, Douglas 'Dallas North' Neubauer) (11006) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\alien.bin
copying amidar.bin from ROMS/ROMS/ROMS\Amidar (1982) (Parker Brothers, Ed Temple) (PB5310) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\amidar.bin
copying assault.bin from ROMS/ROMS/ROMS\Assault (AKA Sky Alien) (1983) (Bomb - Onbase) (CA281).bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\assault.bin
copying asterix.bin from ROMS/ROMS/ROMS\Asterix (AKA Taz) (07-27-1983) (Atari, Jerome Domurat, Steve Woita) (CX2696) (Prototype).bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\asterix.bin
copying asteroids.bin from ROMS/ROMS/ROMS\Asteroids (1981) (Atari, Brad Stewart - Sears) (CX2649 - 49-75163) [no copyright] ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\asteroids.bin
copying atlantis.bin from ROMS/ROMS/ROMS\Atlantis (Lost City of Atlantis) (1982) (Imagic, Dennis Koble) (720103-1A, 720103-1B, IA3203, IX-010-04) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\atlantis.bin
copying bank_heist.bin from ROMS/ROMS/ROMS\Bank Heist (Bonnie & Clyde, Cops 'n' Robbers, Hold-Up, Roaring 20's) (1983) (20th Century Fox Video Games, Bill Aspromonte) (11012) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\bank_heist.bin
copying battle_zone.bin from ROMS/ROMS/ROMS\Battlezone (1983) (Atari - GCC, Mike Feinstein, Brad Rice) (CX2681) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\battle_zone.bin
copying beam_rider.bin from ROMS/ROMS/ROMS\Beamrider (1984) (Activision - Cheshire Engineering, David Rolfe, Larry Zwick) (AZ-037-04) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\beam_rider.bin
copying berzerk.bin from ROMS/ROMS/ROMS\Berzerk (1982) (Atari, Dan Hitchens - Sears) (CX2650 - 49-75168) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\berzerk.bin
copying bowling.bin from ROMS/ROMS/ROMS\Bowling (1979) (Atari, Larry Kaplan - Sears) (CX2628 - 6-99842, 49-75117) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\bowling.bin
copying boxing.bin from ROMS/ROMS/ROMS\Boxing - La Boxe (1980) (Activision, Bob Whitehead) (AG-002, CAG-002, AG-002-04) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\boxing.bin
copying breakout.bin from ROMS/ROMS/ROMS\Breakout - Breakaway IV (Paddle) (1978) (Atari, Brad Stewart - Sears) (CX2622 - 6-99813, 49-75107) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\breakout.bin
copying carnival.bin from ROMS/ROMS/ROMS\Carnival (1982) (Coleco - Woodside Design Associates, Steve 'Jessica Stevens' Kitchen) (2468) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\carnival.bin
copying centipede.bin from ROMS/ROMS/ROMS\Centipede (1983) (Atari - GCC) (CX2676) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\centipede.bin
copying chopper_command.bin from ROMS/ROMS/ROMS\Chopper Command (1982) (Activision, Bob Whitehead) (AX-015, AX-015-04) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\chopper_command.bin
copying crazy_climber.bin from ROMS/ROMS/ROMS\Crazy Climber (1983) (Atari - Roklan, Joe Gaucher, Alex Leavens) (CX2683) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\crazy_climber.bin
copying defender.bin from ROMS/ROMS/ROMS\Defender (1982) (Atari, Robert C. Polaro, Alan J. Murphy - Sears) (CX2609 - 49-75186) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\defender.bin
copying demon_attack.bin from ROMS/ROMS/ROMS\Demon Attack (Death from Above) (1982) (Imagic, Rob Fulop) (720000-200, 720101-1B, 720101-1C, IA3200, IA3200C, IX-006-04) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\demon_attack.bin
copying donkey_kong.bin from ROMS/ROMS/ROMS\Donkey Kong (1982) (Coleco - Woodside Design Associates - Imaginative Systems Software, Garry Kitchen) (2451) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\donkey_kong.bin
copying double_dunk.bin from ROMS/ROMS/ROMS\Double Dunk (Super Basketball) (1989) (Atari, Matthew L. Hubbard) (CX26159) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\double_dunk.bin
copying elevator_action.bin from ROMS/ROMS/ROMS\Elevator Action (1983) (Atari, Dan Hitchens) (CX26126) (Prototype) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\elevator_action.bin
copying enduro.bin from ROMS/ROMS/ROMS\Enduro (1983) (Activision, Larry Miller) (AX-026, AX-026-04) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\enduro.bin
copying fishing_derby.bin from ROMS/ROMS/ROMS\Fishing Derby (1980) (Activision, David Crane) (AG-004) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\fishing_derby.bin
copying freeway.bin from ROMS/ROMS/ROMS\Freeway (1981) (Activision, David Crane) (AG-009, AG-009-04) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\freeway.bin
copying frogger.bin from ROMS/ROMS/ROMS\Frogger (1982) (Parker Brothers, Ed English, David Lamkins) (PB5300) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\frogger.bin
copying frostbite.bin from ROMS/ROMS/ROMS\Frostbite (1983) (Activision, Steve Cartwright) (AX-031) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\frostbite.bin
copying galaxian.bin from ROMS/ROMS/ROMS\Galaxian (1983) (Atari - GCC, Mark Ackerman, Tom Calderwood, Glenn Parker) (CX2684) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\galaxian.bin
copying gopher.bin from ROMS/ROMS/ROMS\Gopher (Gopher Attack) (1982) (U.S. Games Corporation - JWDA, Sylvia Day, Todd Marshall, Robin McDaniel, Henry Will IV) (VC2001) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\gopher.bin
copying gravitar.bin from ROMS/ROMS/ROMS\Gravitar (1983) (Atari, Dan Hitchens, Mimi Nyden) (CX2685) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\gravitar.bin
copying hero.bin from ROMS/ROMS/ROMS\H.E.R.O. (1984) (Activision, John Van Ryzin) (AZ-036-04) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\hero.bin
copying ice_hockey.bin from ROMS/ROMS/ROMS\Ice Hockey - Le Hockey Sur Glace (1981) (Activision, Alan Miller) (AX-012, CAX-012, AX-012-04) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\ice_hockey.bin
copying jamesbond.bin from ROMS/ROMS/ROMS\James Bond 007 (James Bond Agent 007) (1984) (Parker Brothers - On-Time Software, Joe Gaucher, Louis Marbel) (PB5110) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\jamesbond.bin
copying journey_escape.bin from ROMS/ROMS/ROMS\Journey Escape (1983) (Data Age, J. Ray Dettling) (112-006) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\journey_escape.bin
copying kaboom.bin from ROMS/ROMS/ROMS\Kaboom! (Paddle) (1981) (Activision, Larry Kaplan, David Crane) (AG-010, AG-010-04) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\kaboom.bin
copying kangaroo.bin from ROMS/ROMS/ROMS\Kangaroo (1983) (Atari - GCC, Kevin Osborn) (CX2689) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\kangaroo.bin
copying keystone_kapers.bin from ROMS/ROMS/ROMS\Keystone Kapers - Raueber und Gendarm (1983) (Activision, Garry Kitchen - Ariola) (EAX-025, EAX-025-04I - 711 025-725) (PAL).bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\keystone_kapers.bin
copying king_kong.bin from ROMS/ROMS/ROMS\King Kong (1982) (Tigervision - Software Electronics Corporation, Karl T. Olinger - Teldec) (7-001 - 3.60001 VE) (PAL).bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\king_kong.bin
copying koolaid.bin from ROMS/ROMS/ROMS\Kool-Aid Man (Kool Aid Pitcher Man) (1983) (M Network, Stephen Tatsumi, Jane Terjung - Kool Aid) (MT4648) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\koolaid.bin
copying krull.bin from ROMS/ROMS/ROMS\Krull (1983) (Atari, Jerome Domurat, Dave Staugas) (CX2682) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\krull.bin
copying kung_fu_master.bin from ROMS/ROMS/ROMS\Kung-Fu Master (1987) (Activision - Imagineering, Dan Kitchen, Garry Kitchen) (AG-039-04) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\kung_fu_master.bin
copying laser_gates.bin from ROMS/ROMS/ROMS\Laser Gates (AKA Innerspace) (1983) (Imagic, Dan Oliver) (720118-2A, 13208, EIX-007-04I) (PAL).bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\laser_gates.bin
copying lost_luggage.bin from ROMS/ROMS/ROMS\Lost Luggage (Airport Mayhem) (1982) (Apollo - Games by Apollo, Larry Minor, Ernie Runyon, Ed Salvo) (AP-2004) [no opening scene] ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\lost_luggage.bin
copying montezuma_revenge.bin from ROMS/ROMS/ROMS\Montezuma's Revenge - Featuring Panama Joe (1984) (Parker Brothers - JWDA, Henry Will IV) (PB5760) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\montezuma_revenge.bin
copying mr_do.bin from ROMS/ROMS/ROMS\Mr. Do! (1983) (CBS Electronics, Ed English) (4L4478) (PAL).bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\mr_do.bin
copying ms_pacman.bin from ROMS/ROMS/ROMS\Ms. Pac-Man (1983) (Atari - GCC, Mark Ackerman, Glenn Parker) (CX2675) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\ms_pacman.bin
copying name_this_game.bin from ROMS/ROMS/ROMS\Name This Game (Guardians of Treasure) (1983) (U.S. Games Corporation - JWDA, Roger Booth, Sylvia Day, Ron Dubren, Todd Marshall, Robin McDaniel, Wes Trager, Henry Will IV) (VC1007) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\name_this_game.bin
copying pacman.bin from ROMS/ROMS/ROMS\Pac-Man (1982) (Atari, Tod Frye) (CX2646) (PAL).bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\pacman.bin
copying phoenix.bin from ROMS/ROMS/ROMS\Phoenix (1983) (Atari - GCC, Mike Feinstein, John Mracek) (CX2673) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\phoenix.bin
copying video_pinball.bin from ROMS/ROMS/ROMS\Pinball (AKA Video Pinball) (Zellers).bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\video_pinball.bin
copying pitfall.bin from ROMS/ROMS/ROMS\Pitfall! - Pitfall Harry's Jungle Adventure (Jungle Runner) (1982) (Activision, David Crane) (AX-018, AX-018-04) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\pitfall.bin
copying pooyan.bin from ROMS/ROMS/ROMS\Pooyan (1983) (Konami) (RC 100-X 02) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\pooyan.bin
copying private_eye.bin from ROMS/ROMS/ROMS\Private Eye (1984) (Activision, Bob Whitehead) (AG-034-04) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\private_eye.bin
copying qbert.bin from ROMS/ROMS/ROMS\Q-bert (1983) (Parker Brothers - Western Technologies, Dave Hampton, Tom Sloper) (PB5360) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\qbert.bin
copying riverraid.bin from ROMS/ROMS/ROMS\River Raid (1982) (Activision, Carol Shaw) (AX-020, AX-020-04) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\riverraid.bin
copying road_runner.bin from patched version of ROMS/ROMS/ROMS\Road Runner (1989) (Atari - Bobco, Robert C. Polaro) (CX2663) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\road_runner.bin
copying robotank.bin from ROMS/ROMS/ROMS\Robot Tank (Robotank) (1983) (Activision, Alan Miller) (AZ-028, AG-028-04) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\robotank.bin
copying seaquest.bin from ROMS/ROMS/ROMS\Seaquest (1983) (Activision, Steve Cartwright) (AX-022) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\seaquest.bin
copying sir_lancelot.bin from ROMS/ROMS/ROMS\Sir Lancelot (1983) (Xonox - K-Tel Software - Product Guild, Anthony R. Henderson) (99006, 6220) (PAL).bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\sir_lancelot.bin
copying skiing.bin from ROMS/ROMS/ROMS\Skiing - Le Ski (1980) (Activision, Bob Whitehead) (AG-005, CAG-005, AG-005-04) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\skiing.bin
copying solaris.bin from ROMS/ROMS/ROMS\Solaris (The Last Starfighter, Star Raiders II, Universe) (1986) (Atari, Douglas Neubauer, Mimi Nyden) (CX26136) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\solaris.bin
copying space_invaders.bin from ROMS/ROMS/ROMS\Space Invaders (1980) (Atari, Richard Maurer - Sears) (CX2632 - 49-75153) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\space_invaders.bin
copying star_gunner.bin from ROMS/ROMS/ROMS\Stargunner (1983) (Telesys, Alex Leavens) (1005) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\star_gunner.bin
copying surround.bin from ROMS/ROMS/ROMS\Surround (32 in 1) (Bit Corporation) (R320).bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\surround.bin
copying tennis.bin from ROMS/ROMS/ROMS\Tennis - Le Tennis (1981) (Activision, Alan Miller) (AG-007, CAG-007) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\tennis.bin
copying time_pilot.bin from ROMS/ROMS/ROMS\Time Pilot (1983) (Coleco - Woodside Design Associates, Harley H. Puthuff Jr.) (2663) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\time_pilot.bin
copying trondead.bin from ROMS/ROMS/ROMS\TRON - Deadly Discs (TRON Joystick) (1983) (M Network - INTV - APh Technological Consulting, Jeff Ronne, Brett Stutz) (MT5662) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\trondead.bin
copying tutankham.bin from ROMS/ROMS/ROMS\Tutankham (1983) (Parker Brothers, Dave Engman, Dawn Stockbridge) (PB5340) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\tutankham.bin
copying up_n_down.bin from ROMS/ROMS/ROMS\Up 'n Down (1984) (SEGA - Beck-Tech, Steve Beck, Phat Ho) (009-01) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\up_n_down.bin
copying venture.bin from ROMS/ROMS/ROMS\Venture (1982) (Coleco, Joseph Biel) (2457) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\venture.bin
copying pong.bin from ROMS/ROMS/ROMS\Video Olympics - Pong Sports (Paddle) (1977) (Atari, Joe Decuir - Sears) (CX2621 - 99806, 6-99806, 49-75104) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\pong.bin
copying wizard_of_wor.bin from ROMS/ROMS/ROMS\Wizard of Wor (1982) (CBS Electronics - Roklan, Joe Hellesen, Joe Wagner) (M8774, M8794) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\wizard_of_wor.bin
copying yars_revenge.bin from ROMS/ROMS/ROMS\Yars' Revenge (Time Freeze) (1982) (Atari, Howard Scott Warshaw - Sears) (CX2655 - 49-75167) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\yars_revenge.bin
copying zaxxon.bin from ROMS/ROMS/ROMS\Zaxxon (1983) (Coleco) (2454) ~.bin to C:\Users\sarth\.conda\envs\master\lib\site-packages\atari_py\atari_roms\zaxxon.bin
%cd Sections/
d:\Github\Reinforcement_Learning\Sections
DQN with all preprocessing¶
## DQN with all Preprocessing
import os
import gym
import numpy as np
import matplotlib.pyplot as plt
import collections
import cv2
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch as T
#############################################################################
#############################################################################
class ReplayBuffer():
def __init__(self, max_size, input_shape, n_actions):
self.mem_size = max_size
self.mem_cntr = 0
self.state_memory = np.zeros((self.mem_size, *input_shape), dtype = np.float32)
self.new_state_memory = np.zeros((self.mem_size, *input_shape), dtype = np.float32)
self.action_memory = np.zeros(self.mem_size, dtype = np.int64)
self.reward_memory = np.zeros(self.mem_size, dtype = np.float32)
self.terminal_memory = np.zeros(self.mem_size, dtype = np.uint8)
def store_transition(self, state, action, reward, state_, done):
index = self.mem_cntr % self.mem_size
self.state_memory[index] = state
self.action_memory[index] = action
self.reward_memory[index] = reward
self.new_state_memory[index] = state_
self.terminal_memory[index] = done
self.mem_cntr += 1
def sample_buffer(self, batch_size):
max_mem = min(self.mem_cntr, self.mem_size)
batch = np.random.choice(max_mem, batch_size, replace = False)
states = self.state_memory[batch]
actions = self.action_memory[batch]
rewards = self.reward_memory[batch]
states_ = self.new_state_memory[batch]
dones = self.terminal_memory[batch]
return states, actions, rewards, states_, dones
#############################################################################
#############################################################################
def plot_learning_curve(x, scores, epsilons):
fig = plt.figure()
ax = fig.add_subplot(111, label = "1")
ax2 = fig.add_subplot(111, label = "2", frame_on = False)
ax.plot(x, epsilons, color = "C0")
ax.set_xlabel("Training Steps", color = "C0")
ax.set_ylabel("Epsilon", color = "C0")
ax.tick_params(axis = 'x', colors = "C0")
ax.tick_params(axis = 'y', colors = "C0")
N = len(scores)
running_avg = np.empty(N)
for t in range(N):
running_avg[t] = np.mean(scores[max(0, t-100):(t+1)])
ax2.scatter(x, running_avg, color = "C1")
ax2.axes.get_xaxis().set_visible(False)
ax2.yaxis.tick_right()
ax2.set_ylabel('Score', color = "C1")
ax2.yaxis.set_label_position('right')
ax2.tick_params(axis = 'y', colors = "C1")
class RepeatActionAndMaxFrame(gym.Wrapper):
def __init__ (self, env = None, repeat = 4, clip_rewards = False, no_ops = 0.0, fire_first = False):
super(RepeatActionAndMaxFrame, self).__init__(env)
self.repeat = repeat
self.shape = env.observation_space.low.shape
self.frame_buffer = np.zeros_like((2, self.shape))
self.clip_reward = clip_rewards
self.no_ops = no_ops
self.fire_first = fire_first
def step(self, action):
t_reward = 0.0
done = False
for i in range(self.repeat):
obs, reward, done, info = self.env.step(action)
if self.clip_reward:
reward = np.clip(np.array([reward]), -1, 1)[0]
t_reward += reward
idx = i % 2
self.frame_buffer[idx] = obs
if done:
break
max_frame = np.maximum(self.frame_buffer[0], self.frame_buffer[1])
return max_frame, t_reward, done, info
def reset(self):
obs = self.env.reset()
no_ops = np.random.randint(self.no_ops) + 1 if self.no_ops > 0 else 0
for _ in range(no_ops):
_, _, done, _ = self.env.step(0)
if done:
self.env.reset()
if self.fire_first:
assert self.env.unwrapped.get_action_meanings()[1] == 'FIRE'
obs, _, _, _ = self.env.step(1)
self.frame_buffer = np.zeros_like((2, self.shape))
self.frame_buffer[0] = obs
return obs
class PreprocessFrame(gym.ObservationWrapper):
def __init__ (self, shape, env = None):
super(PreprocessFrame, self).__init__(env)
self.shape = (shape[2], shape[0], shape[1])
self.observation_space = gym.spaces.Box(low = 0.0, high = 1.0, shape = self.shape, dtype = np.float32)
def observation(self, obs):
new_frame = cv2.cvtColor(obs, cv2.COLOR_RGB2GRAY)
resized_screen = cv2.resize(new_frame, self.shape[1:], interpolation = cv2.INTER_AREA)
new_obs = np.array(resized_screen, dtype = np.uint8).reshape(self.shape)
new_obs = new_obs / 255.0
return new_obs
class StackFrames(gym.ObservationWrapper):
def __init__(self, env, repeat):
super(StackFrames, self).__init__(env)
self.observation_space = gym.spaces.Box(
env.observation_space.low.repeat(repeat, axis = 0),
env.observation_space.high.repeat(repeat, axis = 0),
dtype = np.float32)
self.stack = collections.deque(maxlen = repeat)
def reset(self):
self.stack.clear()
observation = self.env.reset()
for _ in range(self.stack.maxlen):
self.stack.append(observation)
return np.array(self.stack).reshape(self.observation_space.low.shape)
def observation(self, observation):
self.stack.append(observation)
return np.array(self.stack).reshape(self.observation_space.low.shape)
def make_env(env_name, shape = (84,84,1), repeat = 4, clip_rewards = False, no_ops = 0, fire_first = False):
env = gym.make(env_name)
env = RepeatActionAndMaxFrame(env, repeat, clip_rewards, no_ops, fire_first)
env = PreprocessFrame(shape, env)
env = StackFrames(env, repeat)
return env
#############################################################################
#############################################################################
class DeepQNetwork(nn.Module):
def __init__ (self, lr, n_actions, name, input_dims, chkpt_dir):
super(DeepQNetwork, self).__init__()
self.checkpoint_dir = chkpt_dir
self.checkpoint_file = os.path.join(self.checkpoint_dir, name)
self.conv1 = nn.Conv2d(input_dims[0], 32, 8, stride = 4)
self.conv2 = nn.Conv2d(32, 64, 4, stride = 2)
self.conv3 = nn.Conv2d(64, 64, 3, stride = 1)
fc_input_dims = self.calculate_conv_output_dims(input_dims)
self.fc1 = nn.Linear(fc_input_dims, 512)
self.fc2 = nn.Linear(512, n_actions)
self.optimizer = optim.RMSprop(self.parameters(), lr = lr)
self.loss = nn.MSELoss()
self.device = T.device('cuda:0' if T.cuda.is_available() else 'cpu')
print("My Device: ", self.device)
self.to(self.device)
def calculate_conv_output_dims(self, input_dims):
state = T.zeros(1, *input_dims)
dims = self.conv1(state)
dims = self.conv2(dims)
dims = self.conv3(dims)
return int(np.prod(dims.size()))
def forward(self, state):
conv1 = F.relu(self.conv1(state))
conv2 = F.relu(self.conv2(conv1))
conv3 = F.relu(self.conv3(conv2))
# Shape is BS x n_Filters x H x W
conv_state = conv3.view(conv3.size()[0], -1)
flat1 = F.relu(self.fc1(conv_state))
actions = self.fc2(flat1)
return actions
def save_checkpoint(self):
print('...Saving Checkpoint...')
T.save(self.state_dict(), self.checkpoint_file)
def load_checkpoint(self):
print('...Loading Checkpoint...')
self.load_state_dict(T.load(self.checkpoint_file))
class DQNAgent():
def __init__ (self, gamma, epsilon, lr, n_actions,
input_dims, mem_size, batch_size,
eps_min = 0.01, eps_dec = 5e-7,
replace = 1000, algo = None,
env_name = None, chkpt_dir = 'tmp/dqn'):
self.gamma = gamma
self.epsilon = epsilon
self.lr = lr
self.n_actions = n_actions
self.input_dims = input_dims
self.batch_size = batch_size
self.eps_min = eps_min
self.eps_dec = eps_dec
self.replace_target_cnt = replace
self.algo = algo
self.env_name = env_name
self.chkpt_dir = chkpt_dir
self.action_space = [i for i in range(self.n_actions)]
self.learn_step_counter = 0
self.memory = ReplayBuffer(mem_size, input_dims, n_actions)
self.q_eval = DeepQNetwork(self.lr, self.n_actions,
input_dims = self.input_dims,
name = self.env_name + '_' + self.algo + '_q_eval',
chkpt_dir = self.chkpt_dir)
self.q_next = DeepQNetwork(self.lr, self.n_actions,
input_dims = self.input_dims,
name = self.env_name + '_' + self.algo + '_q_next',
chkpt_dir = self.chkpt_dir)
def choose_action(self, observation):
if np.random.random() > self.epsilon:
state = T.tensor([observation], dtype = T.float).to(self.q_eval.device)
actions = self.q_eval.forward(state)
action = T.argmax(actions).item()
else:
action = np.random.choice(self.action_space)
return action
def store_transition(self, state, action, reward, state_, done):
self.memory.store_transition(state, action, reward, state_, done)
def sample_memory(self):
state, action, reward, new_state, done = self.memory.sample_buffer(self.batch_size)
states = T.tensor(state).to(self.q_eval.device)
rewards = T.tensor(reward).to(self.q_eval.device)
dones = T.tensor(done).to(self.q_eval.device)
actions = T.tensor(action).to(self.q_eval.device)
states_ = T.tensor(new_state).to(self.q_eval.device)
return states, actions, rewards, states_, dones
def replace_target_network(self):
if self.learn_step_counter % self.replace_target_cnt == 0:
self.q_next.load_state_dict(self.q_eval.state_dict())
def decrement_epsilon(self):
self.epsilon = self.epsilon - self.eps_dec if self.epsilon > self.eps_min else self.eps_min
def save_models(self):
self.q_eval.save_checkpoint()
self.q_next.save_checkpoint()
def load_models(self):
self.q_eval.load_checkpoint()
self.q_next.load_checkpoint()
def learn(self, state, action, reward, state_):
if self.memory.mem_cntr < self.batch_size:
return
self.q_eval.optimizer.zero_grad()
self.replace_target_network()
states, actions, rewards, states_, dones = self.sample_memory()
indices = np.arange(self.batch_size)
q_pred = self.q_eval.forward(states)[indices, actions]
q_next = self.q_next.forward(states_).max(dim = 1)[0]
q_next[dones] = 0.0
q_target = rewards + self.gamma*q_next
loss = self.q_eval.loss(q_target, q_pred).to(self.q_eval.device)
loss.backward()
self.q_eval.optimizer.step()
self.learn_step_counter += 1
self.decrement_epsilon()
#############################################################################
#############################################################################
env = make_env('PongNoFrameskip-v4')
best_score = -np.inf
load_checkpoint = False
n_games = 100
agent = DQNAgent(
gamma = 0.99,
epsilon = 1.0,
lr = 0.0001,
input_dims = (env.observation_space.shape),
n_actions = env.action_space.n,
mem_size = 10000,
eps_min = 0.1,
batch_size = 32,
replace = 1000,
eps_dec = 1e-5,
chkpt_dir = 'models/',
algo = 'DQNAgent',
env_name = 'PongNoFrameskip-v4'
)
if load_checkpoint:
agent.load_models()
fname = agent.algo + '_' + agent.env_name + '_lr' + str(agent.lr) + '_' + str(n_games) + '_games'
figure_file = 'plots/' + fname + '.png'
n_steps = 0
scores, eps_history, steps_array = [], [], []
for i in range(n_games):
done = False
score = 0
observation = env.reset()
while not done:
action = agent.choose_action(observation)
observation_, reward, done, info = env.step(action)
score += reward
if not load_checkpoint:
agent.store_transition(observation, action, reward, observation_, int(done))
agent.learn(observation, action, reward, observation_)
observation = observation_
n_steps += 1
scores.append(score)
steps_array.append(n_steps)
avg_score = np.mean(scores[-100:])
print('episode', i, 'score %.1f Avg_Score %.1f Best_Score %.1f epsilon %.2f'%(score, avg_score, best_score, agent.epsilon), 'steps ', n_steps)
if avg_score > best_score:
if not load_checkpoint:
agent.save_models()
best_score = avg_score
eps_history.append(agent.epsilon)
plot_learning_curve(steps_array, scores, eps_history)
<string>:6: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray
My Device: cuda:0
My Device: cuda:0
ipykernel_launcher:287: UserWarning: indexing with dtype torch.uint8 is now deprecated, please use a dtype torch.bool instead. (Triggered internally at ..\aten\src\ATen/native/IndexingUtils.h:30.)
episode 0 score -21.0 Avg_Score -21.0 Best_Score -inf epsilon 0.99 steps 812
...Saving Checkpoint...
...Saving Checkpoint...
episode 1 score -21.0 Avg_Score -21.0 Best_Score -21.0 epsilon 0.98 steps 1784
episode 2 score -20.0 Avg_Score -20.7 Best_Score -21.0 epsilon 0.97 steps 2788
...Saving Checkpoint...
...Saving Checkpoint...
episode 3 score -20.0 Avg_Score -20.5 Best_Score -20.7 epsilon 0.96 steps 3982
...Saving Checkpoint...
...Saving Checkpoint...
episode 4 score -21.0 Avg_Score -20.6 Best_Score -20.5 epsilon 0.95 steps 4802
episode 5 score -21.0 Avg_Score -20.7 Best_Score -20.5 epsilon 0.94 steps 5585
episode 6 score -21.0 Avg_Score -20.7 Best_Score -20.5 epsilon 0.94 steps 6438
episode 7 score -20.0 Avg_Score -20.6 Best_Score -20.5 epsilon 0.93 steps 7342
episode 8 score -21.0 Avg_Score -20.7 Best_Score -20.5 epsilon 0.92 steps 8168
episode 9 score -20.0 Avg_Score -20.6 Best_Score -20.5 epsilon 0.91 steps 9190
episode 10 score -21.0 Avg_Score -20.6 Best_Score -20.5 epsilon 0.90 steps 9982
episode 11 score -21.0 Avg_Score -20.7 Best_Score -20.5 epsilon 0.89 steps 10926
episode 12 score -21.0 Avg_Score -20.7 Best_Score -20.5 epsilon 0.88 steps 11690
episode 13 score -20.0 Avg_Score -20.6 Best_Score -20.5 epsilon 0.87 steps 12594
episode 14 score -21.0 Avg_Score -20.7 Best_Score -20.5 epsilon 0.87 steps 13420
episode 15 score -21.0 Avg_Score -20.7 Best_Score -20.5 epsilon 0.86 steps 14424
episode 16 score -20.0 Avg_Score -20.6 Best_Score -20.5 epsilon 0.84 steps 15538
episode 17 score -18.0 Avg_Score -20.5 Best_Score -20.5 epsilon 0.83 steps 16687
episode 18 score -21.0 Avg_Score -20.5 Best_Score -20.5 epsilon 0.82 steps 17618
episode 19 score -16.0 Avg_Score -20.3 Best_Score -20.5 epsilon 0.81 steps 19103
...Saving Checkpoint...
...Saving Checkpoint...
episode 20 score -20.0 Avg_Score -20.3 Best_Score -20.3 epsilon 0.80 steps 20052
...Saving Checkpoint...
...Saving Checkpoint...
episode 21 score -21.0 Avg_Score -20.3 Best_Score -20.3 epsilon 0.79 steps 20905
episode 22 score -21.0 Avg_Score -20.3 Best_Score -20.3 epsilon 0.78 steps 21840
episode 23 score -20.0 Avg_Score -20.3 Best_Score -20.3 epsilon 0.77 steps 22867
episode 24 score -21.0 Avg_Score -20.4 Best_Score -20.3 epsilon 0.76 steps 23716
episode 25 score -20.0 Avg_Score -20.3 Best_Score -20.3 epsilon 0.75 steps 24855
episode 26 score -19.0 Avg_Score -20.3 Best_Score -20.3 epsilon 0.74 steps 26125
episode 27 score -20.0 Avg_Score -20.3 Best_Score -20.3 epsilon 0.73 steps 27282
episode 28 score -20.0 Avg_Score -20.3 Best_Score -20.3 epsilon 0.72 steps 28453
...Saving Checkpoint...
...Saving Checkpoint...
episode 29 score -19.0 Avg_Score -20.2 Best_Score -20.3 epsilon 0.70 steps 29541
...Saving Checkpoint...
...Saving Checkpoint...
episode 30 score -19.0 Avg_Score -20.2 Best_Score -20.2 epsilon 0.69 steps 30757
...Saving Checkpoint...
...Saving Checkpoint...
episode 31 score -18.0 Avg_Score -20.1 Best_Score -20.2 epsilon 0.68 steps 31997
...Saving Checkpoint...
...Saving Checkpoint...
episode 32 score -20.0 Avg_Score -20.1 Best_Score -20.1 epsilon 0.67 steps 32924
...Saving Checkpoint...
...Saving Checkpoint...
episode 33 score -19.0 Avg_Score -20.1 Best_Score -20.1 epsilon 0.66 steps 34028
...Saving Checkpoint...
...Saving Checkpoint...
episode 34 score -20.0 Avg_Score -20.1 Best_Score -20.1 epsilon 0.65 steps 35266
...Saving Checkpoint...
...Saving Checkpoint...
episode 35 score -20.0 Avg_Score -20.1 Best_Score -20.1 epsilon 0.64 steps 36430
...Saving Checkpoint...
...Saving Checkpoint...
episode 36 score -18.0 Avg_Score -20.0 Best_Score -20.1 epsilon 0.62 steps 37892
...Saving Checkpoint...
...Saving Checkpoint...
episode 37 score -19.0 Avg_Score -20.0 Best_Score -20.0 epsilon 0.61 steps 39056
...Saving Checkpoint...
...Saving Checkpoint...
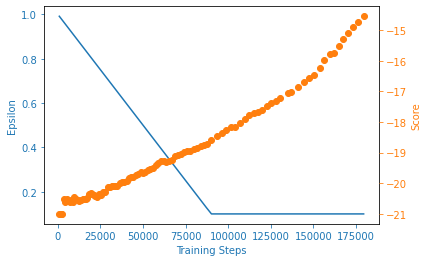
Fig. 15 DQN score with all preprocessing done¶
Tune the hyperparameters.
Using other exploration policies.
Vectorizing environment.
Implement the following,
Double DQN
Dueling DQN
Dueling Double DQN