A Reinforcement Learning Problem¶
Though RL framework is indeed very flexible and general-purpose, the final form varies with each application and algorithmic decision within a project. However, it consistently maintains a fundamental framework, which in turn portrays a general reinforcement learning problem.
Now, we will briefly discuss the constituent elements that make up such a reinforcement learning prolem.
Task
Episodic or Continuous
Performance metric
Fundamental Block
Environment
State
Action
Agent
Reward
Data generation / Exploration-Exploitation Trade-off
Experience Buffer Sampling
Learning Step / Policy Improvement
On-Policy or Off-Policy
Monte-Carlo or Temporal Difference
Algorithm
1. Task¶
Task can be understoon as the objective we are training for. As mentioned earlier, it can include a variety of sequential decision making problem statements.
It is vital to have a clear understanding of the task, as it helps descibe many of the constraints and pointers that help in forming the complete RL problem framework.
1.1 Episodic or continuous¶
Epsiodic tasks are those which have a naturally defined Terminal State, while Continuous Tasks do not.
They have a very strong impact on,
the reward function
the training time and memory complexity
extent of generalization
1.2 Performance metric¶
Even though we have many moving parts within a RL problem framework, with a variety of data structures, algorithms and tasks being explored, we can usually use the following metrics as standards of performance,
Average Reward per episode
Average Length of episode
In addition to above, one can freely set up custom metrics as per requirement, as they do not affect the learning in any manner and only serve the purpose of interpretability and comparision.
2. Fundamental Block¶
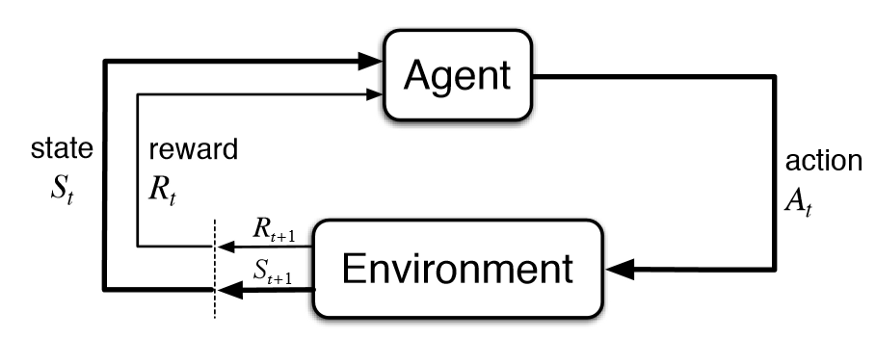
Fig. 9 A fundamental RL block¶
Depending on what algorithm we implement and the complexity to our approach, the solution can be quite varied (and not unique). However, a fundamental block still remains present. It depicts the Agent-Environment interaction.
Even when the framework is scaled up to very high complexity, having a clear grasp over the fundamental interaction can make sure we are scaling up on a stable interaction interface.
2.1 Environment¶
The environment is an entity that the agent can interact with. It defines
the state space of the system,
the observation space for the agent,
the action space,
the state transitions upon executing an action,
the reward function,
the initial state sampling and/or randomization
It is important to remember that any form of state manipulation and/or transition, and associated rewards be defined within the environment itself, and not within agent.
2.2 State¶
The information is represented in the form of state. They can be used to manipulate the format which is stimulating the learning, for example
a sequence of numbers/floats
an image
one-hot encoding, and more
They can be used to manipulate exactly how much our agent can observe while making decisions.
The state transitions can be caused by agent actions, and these transitions can be deterministic or stochastic, and/or associated with noise (consideration of noise can be understood as the system being a partial MDP, not a true one, which is a more realistic case).
2.3 Action¶
An action is the agent’s degree of freedom to act for maximizing the reward. Action executions are usually considered instantaneously, and state evolution during delayed actions would need to be explicitly coded into the environment.
Another important point regarding action is that, if proper care isn’t taken towards exploration-exploitation, hyperparameter setting and selection of algortihm, then the learning can get stuck at a local optima, giving us a near-optimal policy.
2.4 Agent¶
An agent is the brain of a RL framework. It learns a policy which maps states to corresponding action decisions. All calculations which fall under the purview of learning is included here, for example,
hyperparameter initialization
the learning step
action sampling
memory buffer
cooperation or competition with other agents
2.5 Reward¶
A reward is a scalar feedback signal, which tells us when our policy is good and by how much.
To best explain the importance of rewards into the framework, I’ll use the description offerred by Michael Littman in one of his presentations,
He mentions that there are three ways to think about creating intelligent behavior,
”give a man a fish, and he’ll eat for a day”
We program a machine to have the behavior we want it to have (Good old fashioned AI).
But as new problems arise, the machine won’t be able to adapt to new circumstances.
Thus, it requires us to always be there providing the new programs.
”teach a man to fish, and he’ll eat for a lifetime”
If we want the machine to be smart, we can provide training examples, and the machine wirtes its own rules to match those examples (Supervised Learning).
However, generating training examples isn’t always a feasible solution in real-world scenarios.
”give a man a taste for fish, and he’ll figure out how to get fish, even if the details change”
We need not specify the mechanism for achieving a goal. We can just encode the goal and the machine can design its own strategy for achieving it (Reinforcement learning).
This act of encoding the goal characterizes the reward signal, and forms the basis for the reward hypothesis which serves as the basis for all RL tasks.
Another merit of RL here is that the machine would be able to adapt to changing circumstances, for example, it can look for different types of seafood if the one it originally ate is no longer available, or it can go fish to nearby areas if the yield in one place becomes too low.
3. Data generation / Exploration-Exploitation Trade-off¶
Our learning is just as good as the quality of the data we generate out of our agent-environment interaction. Thus, it is very important to take care of this regard, as the performance can transition from a stable agent with good performance to unstable and bad performance with slight changes in the exploration-exploitation trade-off.
Apart from fine tuning the hyperparameters dealing with exploration strategy, we can also try other exploration strategies, or improve upon memory sampling strategies from buffer.
It is important to note that sometimes due to exploration the score can increase or decrease suddenly depending on the nature of the randomly selected action. Thus, as the exploration decays, the score must stabilize to larger values, because if it decays then it impliess that the agent is unable to learn the policy properly (possibly due to reward function and such).
Therefore, the evauation of performance must be done on a purely greedy episode separately.
4. Experience Buffer Sampling¶
Since the agent-environment interaction can generate sequential non-i.i.d. data, thus we muct create a memory buffer, from which the experiences can be sampled for learning in batch. Apart from the obvious memory limit and batch size, the sampling strategies also play an importanct role here.
THe most commonly implemented strategy is random sampling, some others are,
Prioritized sampling based on score
Upper confidence bound based sampling, and more
5. Learning Step / Policy Improvement¶
5.1 On-Policy or Off-Policy¶
Selection the on-policy or off-policy also has subtle changes to the learning process, for example, off-policy inherently promotes further exploration
5.2 Monte-Carlo or Temporal Difference¶
Depending on the nature of the problem, we can go for either MC or TD(0) (or other TD variants).
6. Algorithm¶
There’s no jack of all traits kind of algorithm in RL. Thus, algorithm selection plays an inportant role, which must be adressed at the early stage of the project itself.